
Artificial intelligence (AI) is no longer a figment of the distant, imaginary future, something we think about only when watching The Terminator or reading about Ray Bradbury’s post-apocalyptic smart homes. Whether or not we notice it, AI is everywhere we look: controlling Siri, monitoring social media, and determining our Netflix recommendations. The role it plays in our lives, however, is becoming increasingly crucial as our world becomes more reliant on AI for human-critical fields like medicine, finance, and national security.
Based on the biological neural network, the brain, artificial neural networks are machine learning algorithms created using layers of interconnected artificial neurons that pass along information through an input-output fashion. Beginning around 2012, the convolutional neural network (CNN) rose in popularity as a type of artificial neural network that is particularly suited for image recognition in computer vision [3]. CNNs require labeled training datasets, which are datasets where the input is already matched with a known “correct” output. After processing all the labeled data, the model is able to label unlabeled data in a validation stage using a generated probability distribution.
The problem lies here: though these algorithms are largely successful and widely implemented, they are not immune to external attacks. Adversarial attacks are on the rise, where malicious hackers design inputs (known as adversarial examples) to trick machine learning models into falsely predicting images [5].
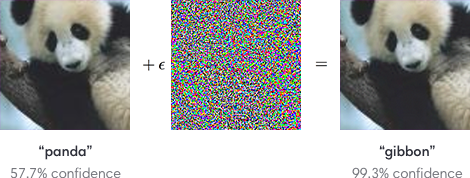
A photo of a panda, when applied with a perturbation, can fool a CNN with high confidence [2].
There are concerns about what this could mean for a variety of fields, such as in autonomous vehicles, where stop signs can be falsely identified as a yield or speed limit sign under the influence of an adversarial example [4].
Several attempts were made to try to solve this problem, but none succeeded with truly promising results. In most adversarial attacks, the attacker will try to manipulate the gradient, a vector-valued function with partial derivative components, by “pushing” the gradient towards the increased probability of a false label. In a procedure known as gradient masking, the gradient is removed by outputting the most likely label instead of the probabilities of each label [1]. For example, instead of an output being “99% likely to be a panda and 1% likely to be a dog,” the output will just be “panda.” This way, minor shifts along the gradient will not indicate to the attacker what perturbation will push the gradient the wrong way because there is no gradient to see. In theory, this should deter attackers, but it doesn’t, and here’s why: the model itself is not becoming more robust, but rather harder to guess by the attacker [1]. An effective way for attackers to circumvent this defense is to create an alternative model with a gradient, and then create adversarial examples and “deploy” them to the target model [1]. Gradient masking is just one of many strategies used to combat adversarial attacks that fail because of an overarching inability to cover the many and varied vulnerabilities of the model, whose very power, its complexity, now acts as its greatest weakness.
A 2020 paper written by IBM researchers explains block switching (BS), a new technique that randomly assigns run times to network layers in an effort to thwart the adversary, as a possible answer to deep learning security concerns [6]. BS involves swapping a portion of model layers with numerous parallel channels, where an active channel is randomly selected during the run time, making the attack harder to predict by the attacker. According to this research, BS yields “more dispersed input gradient distribution… [than] other stochastic defenses” and has a smaller negative impact on training accuracy [6]. In addition to these promising results, this technique can be combined with other strategies to create a stronger, more diversified defense plan.
Though block switching as a strategy is still in its infancy, AI researchers are optimistic about what this could mean for the future of widespread AI. Only when we achieve machine learning security can AI be truly trustworthy, so until then, evil post-apocalyptic smart homes remain a very real possibility.
References:
[1] Goodfellow, Ian. “Attacking Machine Learning with Adversarial Examples.” OpenAI, OpenAI, 7 Mar. 2019, openai.com/blog/adversarial-example-research/.
[2] Goodfellow, Ian J., Jonathon Shlens, and Christian Szegedy. "Explaining and harnessing adversarial examples." arXiv preprint arXiv:1412.6572 (2014).
[3] Krizhevsky, Alex; Sutskever, Ilya; Hinton, Geoffrey E. (2017-05-24). "ImageNet classification with deep convolutional neural networks" (PDF). Communications of the ACM. 60 (6): 84–90. doi:10.1145/3065386. ISSN 0001-0782.
[4] Papernot, Nicolas, et al. "Practical black-box attacks against machine learning." Proceedings of the 2017 ACM on Asia conference on computer and communications security. 2017.
[5] Szegedy, Christian, et al. "Intriguing properties of neural networks. arXiv 2013." arXiv preprint arXiv:1312.6199 (2013).
[6] Wang, Xiao, et al. "Block Switching: A Stochastic Approach for Deep Learning Security." arXiv preprint arXiv:2002.07920 (2020).